实验基于 Kubernetes v1.12.6。
Kubernetes 已经成为容器云平台的操作系统,其稳定性和可靠性非常重要,直接决定平台上所有业务的稳定性和可靠性。 Kubernetes 提供的 hyperkube 能够非常方便地将 Kubernetes 的组件通过容器化的方式运行在 Kubernetes 集群中,等同于用 Kubernetes 的能力,管理和调度自身组件。 同时,Kubernetes 原生提供 HA 能力,组件通过 Kubernetes 管理,更加能够保证集群的可靠性。
本文将介绍两种监控 Kubernetes 集群健康状况的方案,并对它们各自的优劣进行对比分析。
Kubernetes Component Status API
Kubernetes 各自组件都提供 Health check 的 API,同时 Apiserver 也提供对部分组件的健康状况监控的 API。
-
Apiserver
Request:
GET /healthzResponse:
ok -
ETCD
Request:
GET /healthz/etcdResponse:
ok -
All Components
Request:
GET /api/v1/componentstatusesResponse:
{ "kind": "ComponentStatusList", "apiVersion": "v1", "metadata": { "selfLink": "/api/v1/componentstatuses" }, "items": [ { "metadata": { "name": "controller-manager", "selfLink": "/api/v1/componentstatuses/controller-manager", "creationTimestamp": null }, "conditions": [ { "type": "Healthy", "status": "True", "message": "ok" } ] }, { "metadata": { "name": "scheduler", "selfLink": "/api/v1/componentstatuses/scheduler", "creationTimestamp": null }, "conditions": [ { "type": "Healthy", "status": "True", "message": "ok" } ] }, { "metadata": { "name": "etcd-2", "selfLink": "/api/v1/componentstatuses/etcd-2", "creationTimestamp": null }, "conditions": [ { "type": "Healthy", "status": "True", "message": "{\"health\": \"true\"}" } ] }, { "metadata": { "name": "etcd-0", "selfLink": "/api/v1/componentstatuses/etcd-0", "creationTimestamp": null }, "conditions": [ { "type": "Healthy", "status": "True", "message": "{\"health\": \"true\"}" } ] }, { "metadata": { "name": "etcd-1", "selfLink": "/api/v1/componentstatuses/etcd-1", "creationTimestamp": null }, "conditions": [ { "type": "Healthy", "status": "True", "message": "{\"health\": \"true\"}" } ] }, { "metadata": { "name": "etcd-3", "selfLink": "/api/v1/componentstatuses/etcd-3", "creationTimestamp": null }, "conditions": [ { "type": "Healthy", "status": "True", "message": "{\"health\": \"true\"}" } ] } ] }
componentstatuses API 只能提供对控制面组件(Controller manager,Scheduler,ETCD)的监控,对于节点上组件(Kubelet,Kube-proxy)无法进行监控。这种方案要求所有控制面组件跟 Apiserver 部署在同一台机器上,因为这个局限性,社区早在 2015 就有人提出废弃这个 API 的提议,但是这个提议到目前都还没有落实。
开源项目 k8s-healthcheck 就是基于这个思路,实现对 Kubernetes 集群健康状况的监控。
Kubernetes + Prometheus
下面介绍基于 Kubernetes 和 Prometheus 实现的集群健康状况监控的一种解决方案。该方案充分发挥 Kubernetes 和 Prometheus 各自的优势,具有更强大的能力和更灵活的扩展性,基于该方案能够很容易地增加可视化、报警等功能。 该方案的基本原理如下:
- Kubernetes 所有组件 HA 部署,保证整个集群的高可用。
- 所有组件配置 liveness probe,由 Kubernetes 帮忙做所有实例的 health check。如果 health check 不过,会自动重启实例。
- 所有组件暴露 metrics 接口,由 Prometheus 监控所有实例是否正常。
Kubernetes 各组件的 Healthz 和 Metrics API 如下表所示:
| Components | Healthz API | Metrics API |
|---|---|---|
| Apiserver | :6443/healthz | :6443/metrics |
| Controller Manager | :10252/healthz | :10252/metrics |
| Scheduler | :10251/healthz | :10251/metrics |
| Kube-proxy | :10249/healthz | :10249/metrics |
| Kubelet | :10248/healthz | :10250/metrics |
| ETCD | :2379/healthz | :2379/metrics |
所有 Kubernetes 组件的 Healthz API 与 Metrics API 的端口默认都是一致的,只有 Kubelet 例外。
同时,Kube-proxy 存在缺陷 kubernetes/kubernetes#72682,需要注意 Kubernetes 的版本。
部署组件的时候,需要注意如下事项:
- Pod 加上 Prometheus 需要的 annotations:
prometheus.io/scrape和prometheus.io/port。 - Pod 配置 livenessProbe 的健康检查。
- 根据需要合理配置绑定 address 对外可访问的范围,尽量保证安全。
以 Apiserver 为例,其 manifest 如下:
apiVersion: v1
kind: Pod
metadata:
name: kube-apiserver
namespace: kube-system
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
prometheus.io/scrape: "true"
prometheus.io/port: "6443"
spec:
hostNetwork: true
containers:
- name: kube-apiserver
image: devops.cargo.io/library/hyperkube:v1.12.6
imagePullPolicy: IfNotPresent
resources:
requests:
cpu: 250m
memory: 10Mi
command:
- /hyperkube
- apiserver
- --kubelet-preferred-address-types=[InternalDNS,InternalIP,ExternalDNS,ExternalIP,Hostname]
- --apiserver-count=3
- --insecure-bind-address=127.0.0.1
# - --insecure-port=8080
- --insecure-port=0
- --bind-address=192.168.21.100
- --secure-port=6443
- --etcd-servers=https://192.168.21.99:2379,https://192.168.21.100:2379,https://192.168.21.101:2379
- --etcd-servers-overrides=/events#https://192.168.21.99:2381;https://192.168.21.100:2381;https://192.168.21.101:2381
- --etcd-cafile=/etc/kubernetes/etcd/ca.crt
- --etcd-certfile=/etc/kubernetes/etcd/etcd.crt
- --etcd-keyfile=/etc/kubernetes/etcd/etcd.key
- --service-node-port-range=30000-32767
- --service-cluster-ip-range=10.254.0.0/16
- --admission-control=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,ValidatingAdmissionWebhook,MutatingAdmissionWebhook,AlwaysPullImages,NodeRestriction,DenyEscalatingExec,PodSecurityPolicy,EventRateLimit
- --cors-allowed-origins=.*
# - --token-auth-file=/etc/kubernetes/tokens/tokens.csv
# - --basic-auth-file=/etc/kubernetes/tokens/basic-auth.csv
- --authorization-mode=Node,RBAC
- --client-ca-file=/etc/kubernetes/certs/ca.crt
- --tls-cert-file=/etc/kubernetes/certs/server.crt
- --tls-private-key-file=/etc/kubernetes/certs/server.key
- --allow-privileged=true
- --v=2
- --runtime-config=extensions/v1beta1/networkpolicies,batch/v2alpha1,admissionregistration.k8s.io/v1alpha1
- --anonymous-auth=true
- --proxy-client-cert-file=/etc/kubernetes/certs/webhook-client.crt
- --proxy-client-key-file=/etc/kubernetes/certs/webhook-client.key
- --requestheader-client-ca-file=/etc/kubernetes/certs/ca.crt
- --feature-gates=PersistentLocalVolumes=true,ExpandInUsePersistentVolumes=true
- --endpoint-reconciler-type=lease
- --enable-bootstrap-token-auth
- --profiling=false
- --audit-log-path=/var/log/apiserver/audit.log
- --audit-log-maxage=30
- --audit-log-maxbackup=10
- --audit-log-maxsize=100
- --audit-policy-file=/etc/kubernetes/audit-policy.yml
- --service-account-lookup=true
- --admission-control-config-file=/etc/kubernetes/admission-control.yml
- --kubelet-certificate-authority=/etc/kubernetes/certs/ca.crt
- --kubelet-client-certificate=/etc/kubernetes/certs/kubelet-client.crt
- --kubelet-client-key=/etc/kubernetes/certs/kubelet-client.key
- --repair-malformed-updates=false
- --insecure-port=0
- --experimental-encryption-provider-config=/etc/kubernetes/encryption-config.yml
- --service-account-key-file=/etc/kubernetes/keys/sa.pub
ports:
- containerPort: 6443
hostPort: 6443
name: https
- containerPort: 7080
hostPort: 7080
name: http
- containerPort: 8080
hostPort: 8080
name: local
livenessProbe:
httpGet:
scheme: HTTPS
host: 192.168.21.100
path: /healthz
port: 6443
initialDelaySeconds: 15
timeoutSeconds: 15
volumeMounts:
- mountPath: /etc/kubernetes
name: etckube
readOnly: true
- mountPath: /var/log/apiserver
name: log
volumes:
- hostPath:
path: /etc/kubernetes
name: etckube
- hostPath:
path: /var/log/apiserver
name: log
Prometheus 具有 Kubernetes 资源发现的能力,需要根据官方配置文档进行规则的配置。 然后就可以在 Prometheus 界面中的【Status】->【Targets】 界面中看到各组件的健康状况,或者通过 Prometheus 提供的 targets api 获得各监控对象的健康状况。
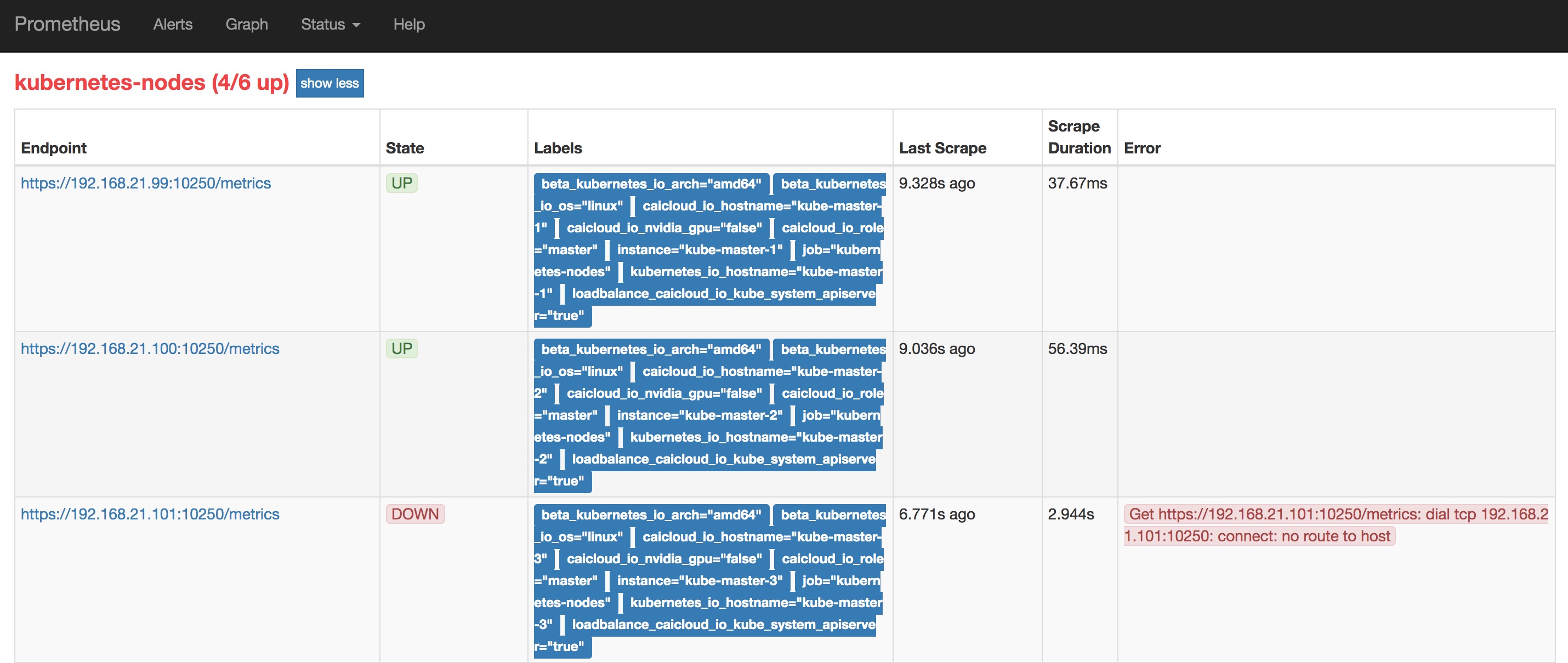
下面以包含节点和 pod 的配置文件为例:
global:
scrape_interval: 10s
scrape_timeout: 10s
evaluation_interval: 10s
scrape_configs:
- job_name: kubernetes-nodes
scrape_interval: 10s
scrape_timeout: 10s
metrics_path: /metrics
scheme: https
kubernetes_sd_configs:
- role: node
tls_config:
ca_file: /secrets/kubelet/ca
cert_file: /secrets/kubelet/cert
key_file: /secrets/kubelet/key
insecure_skip_verify: false
relabel_configs:
- separator: ;
regex: __meta_kubernetes_node_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_node_address_LegacyHostIP]
separator: ;
regex: (.*)
target_label: host_ip
replacement: $1
action: replace
- job_name: kubernetes-pods
scrape_interval: 10s
scrape_timeout: 10s
metrics_path: /metrics
scheme: http
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
separator: ;
regex: "true"
replacement: $1
action: keep
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
separator: ;
regex: (.+)
target_label: __metrics_path__
replacement: $1
action: replace
- source_labels: [__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
separator: ;
regex: ([^:]+)(?::\d+)?;(\d+)
target_label: __address__
replacement: $1:$2
action: replace
- separator: ;
regex: __meta_kubernetes_pod_label_(.+)
replacement: $1
action: labelmap
- source_labels: [__meta_kubernetes_pod_name]
separator: ;
regex: (.*)
target_label: pod_name
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_host_ip]
separator: ;
regex: (.*)
target_label: host_ip
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_namespace]
separator: ;
regex: (.*)
target_label: kubernetes_namespace
replacement: $1
action: replace
- source_labels: [__meta_kubernetes_pod_annotation_helm_sh_namespace, __meta_kubernetes_pod_annotation_helm_sh_release]
separator: ;
regex: (.+);(.+)
target_label: cps_appkey
replacement: $1/$2
action: replace
配置 Prometheus 时,需要注意如下事项:
- 根据资源的特点,选择合适的资源发现机制。
- 如果是以 HTTPS 端口暴露的 metrics,需要配置证书。
Comparison
上面介绍了两种监控 Kubernetes 集群健康状况的方案,
| Solutions | Advantages | Disadvantages |
|---|---|---|
| Kubernetes Component Status API | * 使用简单 * 不依赖 Prometheus |
* 可扩展性差 * Kubernetes 组件必须部署的在同一台机器上 * 只能获得控制面组件的整体状态 |
| Kubernetes + Prometheus | * 使用复杂 * 可扩展性强 * 可以精细到所有组件的所有实例状态 |
* Kubernetes 必须容器化部署 * 依赖 Prometheus |